- created an Ubuntu Server (10.04 x64) LAMP Virtual Machine using VMWare Fusion on an iMac
- installed phpmyadmin on the VM to allow access to MySQL from my Web browser, and tested this to be sure I could access MySQL in the VM guest from Firefox on the VM host
- uncompressed and unarchived the chembl_08_mysql.tar.gz download file in the VM
- the resulting folder contains an INSTALL file which tells you to create a database and execute the chembl_08.mysqldump.sql file which loads the database using CREATE TABLE and INSERT statements
- logged into phpmyadmin from the VM host Firefox and checked that I could browse the ChEBML MySQL data ... it looked fine, there's a screenshot below showing there are 7 million records in the tables as well as a screenshot of the MySQL data model
- for licensing reasones, TopBraid cannot distribute the MySQL JDBC driver so I downloaded the mysql-connector.jar and place it in the TBC workspace root folder (TBC help explained this and included links to the MySQL Web site)
- started TopBraid Composer and created a new project called ChEMBL
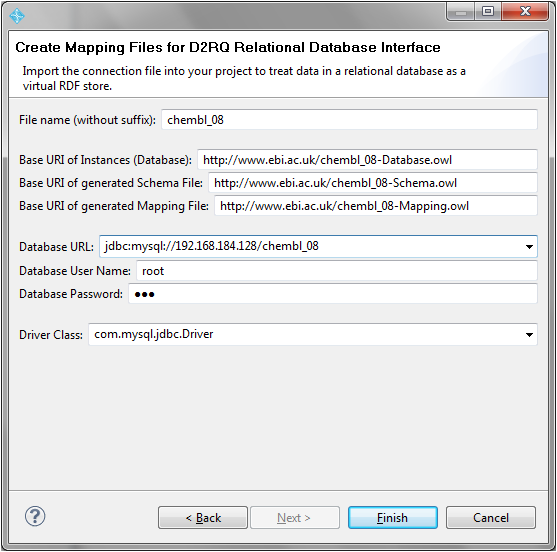
- Selected the project and Import, Create Mapping Files for D2RQ Relational Database Interface
- filled in the filename of chembl_08, , base URIs of http://www.ebi.ac.uk/chembl_08-xxx.owl, database URL/database user/password and MySQL JDBC driver class
- Selected Finish and held my breath ... and after a couple of minutes .. Success!



I won't pretend it's fast to do general instance data browsing - I set my TBC to bring back 30,000 triples at a time to get lots of data, however doing SPARQL queries works pretty quickly. I'm now off to modify the D2RQ mapping to fit with another ontology, but the D2RQ approach to data integration is clearly a powerful and useful capability.

The default mapping creates usable URIs that enable SPARQL queries across classes, so I'm off to a good start. I'll update this post if the D2RQ mapping changes turn out to be interesting.
No comments:
Post a Comment